 Numbers
Numbers  Comments Off on Number Magic – An Explanation of Bendford’s Law
Comments Off on Number Magic – An Explanation of Bendford’s Law Number Magic – An Explanation of Bendford’s Law
Earlier this year, a colleague of mine sent me an email on Bendford’s Law. He had run across it somewhere and was fascinated by it. It seems counterintuitive that small digits would occur more frequently in the leading digits of arbitrary numerical data. One is tempted to think that arbitrary data would be made up of arbitrary digits, but that turns out not to be the case. It’s a genuine numerical phenomenon, and below I have provided a couple of ways to explain it. I point out that, utlimately, this law results from the notation that we use to represent real values.
Upon learning about Bendford’s Law, my colleague decided to put it to a test. So he grabbed an ENDF file, endf66a, and pulled as many values as he could from it. (ENDF stands for “Evaluated Nuclear Data File.” It is a large database of nuclear data, such as cross-sections of various nuclides. For our purposes here, it is a large collection of real-world numerical data.) He collected the leading digit in the mantissa of each floating-point number in the file and examined the frequency of occurrence of each digit. The plot of the results that he produced is shown below.

After seeing his empirical verification of this law, I tried to explain why this law works in a couple of ways.
The first way is to consider the population of data, and here we’re talking about values that span multiple orders of magnitude. For example, if we were talking about lengths, the list could include values measured in centimeters, meters, and kilometers. Now for all of these units to be represented in our population we’d need the number of values expressed in centimeters to be roughly equivalent to the number of values expressed in kilometers. Naturally, such a population wouldn’t even come close to being distributed uniformly over the range of values—there are simply too many centimeters in a kilometer to sample from them in the same way that one would sample over centimeters in one meter. Mathematically, this means that, if \(f(x)\) is the probability density function (p.d.f.) of our population, then\[
\int_{10\,\text{cm}}^{1\,\text{m}} f(x)\,dx \approx
\int_{100\,\text{m}}^{1\,\text{km}} f(x)\,dx
\]which means that\[
\bar f_{(1\,\text{m})} \approx 1000\times\bar f_{(1\,\text{km})}
\]where \(\bar f_{(a)}\) is the average value of the p.d.f. over the neighborhood where \(x \approx a\).
Therefore, it makes sense to look at the value of \(f(x) \cdot x\) plotted versus \(x\) on a semi-log scale, keeping in mind that the probability of \(X\) (a random value drawn from the population) being between \(x_1\) and \(x_2\) is\[
P(x_1 < X < x_2) = \ln(10) \int_{\log_{10}(x_1)}^{\log_{10}(x_2)}
f(10^\xi)\cdot 10^\xi\,d\xi
\]That is, when \(f(x) \cdot x\) is plotted versus \(x\), with a logarithmic scale for \(x\), the area under the curve represents the relative probability of \(X\) being in a particular region. (\(\xi\) gives the linear distance along the logarithmic scale: \(\xi = \log_{10}x\).)
A (made-up) example of such a distribution is shown below.

Here the regions where the leading digit would be 1 are marked off. Compare this to the same figure with the regions where the leading digit would be 5 are highlighted.
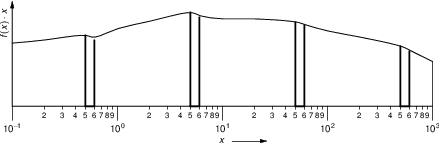
As we can see, the areas marked off in in the first figure are significantly larger than the areas marked off in the second, which means that 1 is more likely than 5 to show up as the first digit of a number that is randomly drawn from this distribution, and this is the case for many collections of numbers that span multiple scales.
But perhaps someone objects to the p.d.f. that I used as an example. OK. Then consider this. To simplify the situation let’s consider only integers and let’s look at the range of integers from 0 to 9. If I have a population of these integers that is uniformly distributed, then any random variable that I produce is as likely to be one digit as another. But what happens if I double my range of possibilities by expanding to the right?
Now, I’m looking at the range of numbers from 0 to 19. Once again, if the distribution is uniform, I’m equally as likely to draw any of the numbers, but now the probability of drawing a number with 1 as the leading digit has changed from 10% to 55%! Over half of the time I’m going to get a number that starts with 1.
This example is contrived, of course, but it readily generalizes. For example, consider what happens if I expand the range to extend from 0 to 49. Although the probability of getting a number that begins with a 1 is no longer 55%, it’s still larger than getting a number that begins with a 5, 6, 7, 8, or 9.
This phenomenon is an artifact of the way we represent real values, not the real values themselves. To see this, it is instructive to consider just one number—for example, the fine-structure constant:\[
\alpha \approx 7.297\times 10^{-3}
\]This is a physical constant. It’s dimensionless. There is no mathematical basis for this constant. As Richard Feynmann once wrote,
It’s one of the greatest damn mysteries of physics: a magic number that comes to us with no understanding by man. You might say the “hand of God” wrote that number, and “we don’t know how He pushed his pencil.”
So this is about an arbitrary a number as one can find. It happens to begin with a 7, not a 1, but that’s just because we use a number system with ten digits. (Ignore, for the moment, that its reciprocal, \(\alpha^{-1} \approx 137.036\), an equally arbitrary number, does begin with a 1.) The number is what it is, regardless of how we write it. We can think of it as a single point on a line that represents all real numbers (the \(x\)-axis of the complex plane). What digits we use to write that number depend on where we lay down the grid lines that denote 1, 2, 3, and so on. If the real values are scaled logarithmically, this line looks like the following:  The point that is \(\alpha\) also is shown above and falls between the ticks for 7 and 8, resulting in a number that begins with 7. But what happens when a different base (number of digits) is used to represent the same number. In octal (base 8, which is often used in computer science, because \(8 = 2^3\)), the real line looks like
The point that is \(\alpha\) also is shown above and falls between the ticks for 7 and 8, resulting in a number that begins with 7. But what happens when a different base (number of digits) is used to represent the same number. In octal (base 8, which is often used in computer science, because \(8 = 2^3\)), the real line looks like  (Keep in mind that now the octal “10” is really an “8” in decimal notation.) In this system of numbers, the numerical representation of \(\alpha\) begins with a 3. If we double the number of digits to 16 (hexadecimal), we find the following:
(Keep in mind that now the octal “10” is really an “8” in decimal notation.) In this system of numbers, the numerical representation of \(\alpha\) begins with a 3. If we double the number of digits to 16 (hexadecimal), we find the following:  The leading digit is now 1.
The leading digit is now 1.
It is important to note that the real line itself and all of the real values it represents, including \(\alpha\), haven’t changed. They are the same in all three diagrams. By changing the number of digits in our number system, we change only where the grid lines (tick marks) are located. All of these number systems agree on the location of 1 (and zero and infinity), but everything else changes. Below, I have tabulated the value of \(\alpha\) for number systems with 3 to 16 digits (base 3 to base 16):
| Base | \(\alpha\) |
|---|---|
| 3 | 1.210e-12 |
| 4 | 1.313e-10 |
| 5 | 4.240e-4 |
| 6 | 1.324e-3 |
| 7 | 2.334e-3 |
| 8 | 3.571e-3 |
| 9 | 5.278e-3 |
| 10 | 7.297e-3 |
| 11 | 9.793e-3 |
| 12 | 1.074e-3 |
| 13 | 1.305e-2 |
| 14 | 1.605e-2 |
| 15 | 1.996e-2 |
| 16 | 1.DE4e-2 |
In 8 out of the 14 number schemes (57%), the representation of \(\alpha\) begins with a 1. This is not surprising when you think about it, because although the locations of the grid lines change, the structure of the grid lines remains similar. The space along the (logarithmically scaled) real line where a 1 is the leading digit is always the largest space. Therefore, 1 is the most likely leading digit, regardless of the base.
For a truly arbitrary number, chosen without any restrictions, it is not difficult to predict that the likelihood of the digit \(n\) being the first digit is\[
P(n) = \log_b(n+1) – \log_b(n) \] where \(b\) is the base of the number system being used. This can be deduced geometrically from the figures above.
As long as one uses a notation system for numbers consisting of a series of symbols in which each successive symbol in the series constitutes a value that is \(b\) times smaller than the symbol before it (where \(b\) is the number of symbols used), the symbol denoting the smallest (non-zero) value (in our case, 1) will be the most likely symbol to appear first in the series.